注:本文整合实验设计、分析方法及数据清洗的核心逻辑,涵盖电商、用户行为等多场景。案例与工具均来自行业实践,可快速复用! 🔗完整方法库参考[[2][6]11。
“可视化案例直击痛点!用漏斗图定位流失环节后,我们转化率提升了22%🚀 方法论比工具更重要!” [[1]5
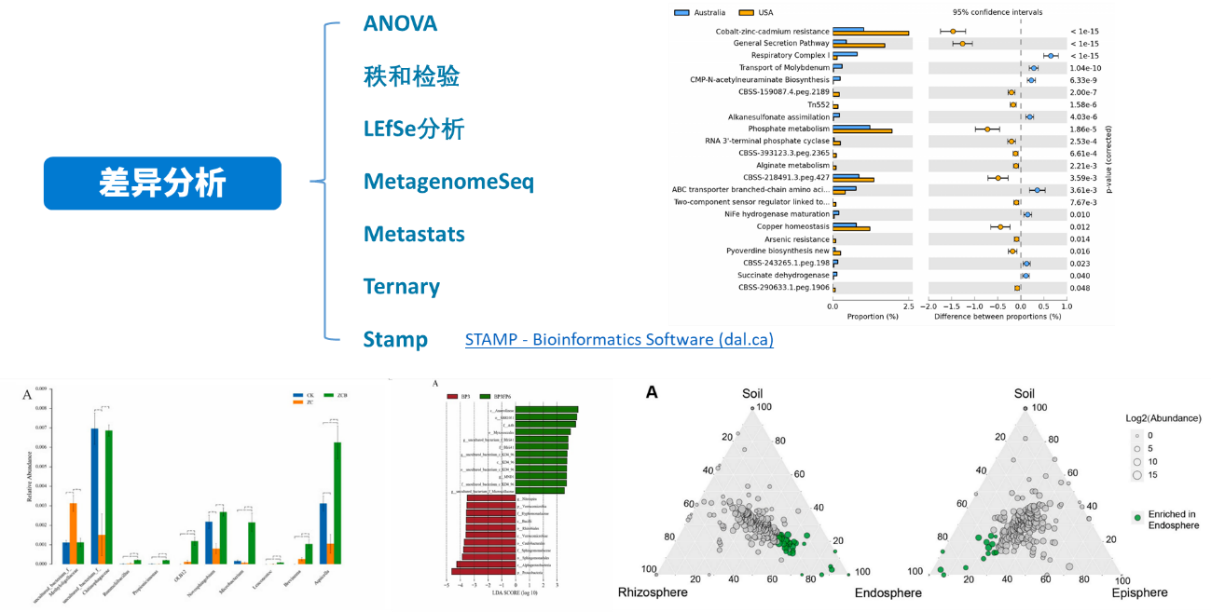
非参数检验部分解决了我的论文难题!终于搞懂了秩和检验的应用场景👏 [[2]11
📊 数据分析方法实验:从设计到落地的全流程解析 🔍
🔬 一、实验设计:科学验证的基石
- 目标指标定义
- 核心KPI:根据业务场景选择关键指标,如电商促销实验关注销售额、转化率、利润额1。需与AI协作验证指标合理性,避免“伪相关”干扰。
- 动态调整:若新策略未显著提升销售(如1案例),需结合用户行为数据(点击率、购物车添加量)深挖原因。
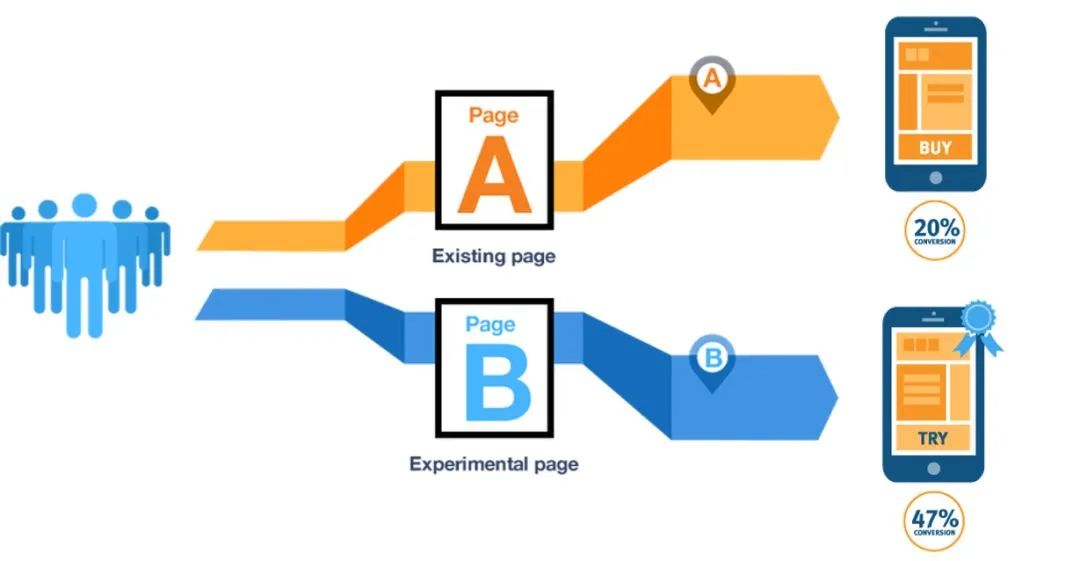
- AB测试框架
- 随机分组:用户随机分为对照组(A组)和实验组(B组),确保样本特征均衡1。
- 周期与样本:实验周期通常≥7天,覆盖用户行为周期;样本量需兼顾代表性与统计显著性1。
- 干扰控制:固定商品、渠道等变量,选择非假期时段,确保结果仅受策略影响1。
⚙️ 二、关键技术方法:多维验证逻辑
- 假设检验
- 参数检验:数据符合正态分布时,用T检验/ANOVA分析组间差异(如促销活动对销售额的影响)2。
- 非参数检验:数据分布未知时,采用秩和检验、卡方检验(如用户满意度等级分析)2。
- 回归与归因
- 多元线性回归:量化多个变量对目标指标的影响(如广告投入、价格调整与销量的关系)2。
- Logistic回归:适用于离散因变量(如用户是否购买的二分类问题)2。
- 聚类分析
- 用户分群:通过R型聚类(指标聚类)划分用户行为模式,Q型聚类(样本聚类)识别高价值客群2。
🧼 三、数据清洗:高质量结果的保障
- 缺失值处理:
- 删除缺失率>60%的字段,数值型数据用均值/回归填充,分类数据用众数填补6。
- 异常值修正:
- 箱线图识别异常值(如年龄填200岁),结合业务逻辑修正或剔除6。
- 格式标准化:
- 统一日期、数值格式,去除文本空格(避免VLOOKUP失败)6。
📈 四、可视化与落地
- 结果呈现
- 动态图表:用折线图展示实验组/对照组的趋势对比,漏斗图分析转化率瓶颈[[1]5。
- 显著性标注:在图表中标注P值(如P<0.05即效果显著),降低理解门槛1。
- 业务建议
- 因果推断:若策略无效(如1中的促销未提升销售),需排查流量质量或用户需求匹配度。
- 迭代方向:建议小步快跑式优化,例如调整促销力度而非全盘推翻8。
💬 网友热评:
- @数据狂魔
:
“实验设计部分太实用!尤其是AB测试的干扰控制,之前忽略了节假日因素导致偏差… 立刻收藏🌟” [[1]8

相关问答
- 实验数据分析方法有哪些
- 答:
1. 聚类分析 聚类分析是将物理或抽象对象分组为多个由类似对象组成的类的分析过程。这一过程涉及将数据自动分类到不同的类或簇中,使得同一簇内的对象具有高度相似性,而不同簇的对象则差异显著。聚类分析是一种探索性分析方法,无需预先设定分类标准。由于采用的聚类方法不同,不同研究者可能会对同一数据集得到不同的聚类结果。2. 因子分析 因子
- 科研常用的实验数据分析与处理方法
- 答:方差分析(ANOVA)是一种显著性检验方法,用于比较两个或多个样本均数的差异。它分析数据波动的原因,识别对观测变量有显著影响的可控因素。实验数据处理通常采用列表法或作图法。列表法将实验数据和中间计算结果按顺序排列成表格,便于分析和发现规律性,有助于检查实验问题。设计记录表格时需注意合理布局、清...
- 科研常用的实验数据分析
- 答:1. 聚类分析 - 数据的自然分类 聚类分析,就像自然界的生物分类,是将数据对象按照相似性分门别类的过程。它不预设类别,而是从数据中寻找内在结构,每个簇内的对象相似度极高,而簇与簇间差异显著。不同的研究者可能会基于不同的方法得出各异的分类结果,但都是从数据中挖掘潜在的秩序。2. 因子分析...
文章来源: 用户投稿版权声明:除非特别标注,否则均为本站原创文章,转载时请以链接形式注明文章出处。





